
The token economy has a training problem
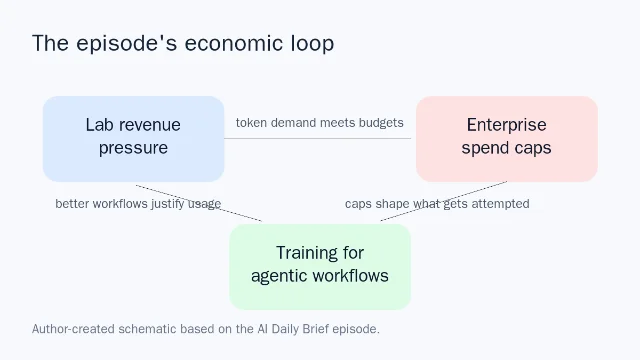
Nathaniel Whittemore argues that the AI boom now depends on a new layer of worker capability: enterprises are capping token spend just as labs need usage to keep rising, so training people to manage agents well becomes the bridge between infrastructure spending and real economic value.

The useful way to read Nathaniel Whittemore's June 16 episode of The AI Daily Brief is not as a training-industry pitch. It is a balance-sheet argument about the AI boom: labs need token usage to keep rising, enterprises are starting to cap spend, and the only bridge between those two facts is better human skill at using agents. The episode was published on June 16, 2026 under the title "Why Only AI Training Can Save the Economy" 1.
콘텐츠 카드를 불러오는 중…

The central claim: access is no longer enough
Whittemore frames AI training as the process of closing "the capability gap between what AI could be doing" and the value people actually get from it 1. That distinction matters. In 2023 and 2024, the corporate AI adoption question was mostly access: who has Copilot, ChatGPT Enterprise, Claude, or a sanctioned internal tool? In this episode, he argues that access has become the easy part.
The harder question is whether workers can move from assisted AI to agentic AI. Assisted AI helps with drafts, summaries, search, or analysis. Agentic AI takes longer-running goals, uses tools, produces artifacts, and may run multiple sessions in parallel. Whittemore's thesis is that the economic value of the second category will not appear just because companies buy licenses. People have to learn how to frame work, delegate it, inspect intermediate outputs, manage context, and decide when a task deserves expensive frontier-model tokens.
That is why the episode's bombastic title has a narrower meaning than it first appears to. He is not saying a training course can mechanically rescue GDP. He is saying the AI investment cycle now depends on a much broader base of workers learning to create enough valuable usage to justify the infrastructure being built around them.
The macro pressure behind the argument
The episode's first move is to make AI infrastructure feel less like a tech-sector story and more like a macroeconomic dependency. Whittemore says AI data centers, hardware, and networking reached 1.4% of U.S. GDP in Q1 2026, up from 0.7%, and he cites St. Louis Fed data suggesting AI investment accounted for 39% of marginal GDP growth over the trailing four quarters 1. He also says big-tech AI capex will pass $800 billion in 2026, with David Sacks arguing that the spend could amount to a 2.5% GDP tailwind this year and 3% next year 1.
The important part is not whether every number survives independent scrutiny. The important part is the mechanism he is trying to isolate: infrastructure spending is increasingly justified by lab revenue growth, and lab revenue growth increasingly depends on token consumption rather than simple seat counts.
| Pressure point in the episode | What Whittemore says | Why it changes the adoption question |
|---|---|---|
| Seat math | $20 to $200 per worker per month cannot justify trillions of dollars in infrastructure (episode). | The business model needs heavier, more valuable usage than basic subscriptions. |
| Agentic usage | Per-person economics could move from hundreds to thousands of dollars per month when agents do longer work (episode). | Training has to teach delegation and oversight, not just prompting. |
| Token scarcity | He cites estimates that $200 plans could allow far more token value than their sticker price implied (episode). | Subsidized experimentation is giving way to budget discipline. |
This is the strongest part of the episode. It ties together two stories that are often discussed separately: the enormous AI capex wave and the day-to-day reality of companies discovering that advanced model usage can burn through budgets quickly. If those stories collide, the result is not simply "use less AI." It is a search for ways to make expensive usage obviously worth it.
Why token efficiency cuts both ways
Whittemore spends a large portion of the episode on what he calls the move from the "token subsidy era" to the "token scarcity era" 1. In the old regime, vendors could blur the real cost of heavy usage behind simple subscription pricing. In the new regime, usage-based billing, caps, model routing, cheaper models, and post-trained specialist models all become normal tools of financial control.
He gives several examples. GitHub Copilot moved toward usage-based billing for agentic sessions. Google added usage limits behind changes to premium tiers. Anthropic drew developer backlash when third-party harness usage shifted toward usage-based billing. Enterprises then responded with their own controls: Uber, in his telling, blew through its AI budget in the first four months and moved to a $1,500 monthly cap per employee 1.
The subtle point is that efficiency is not automatically good for the frontier labs. If enterprises route more work to cheaper models, post-train their own domain systems, or cap usage before employees learn to find high-value agentic workflows, token growth may slow even while interest in AI remains high. Whittemore cites Factory's model-routing feature as saving $13 million in its first 30 days of private preview, and he points to companies experimenting with cheaper Chinese models and post-trained open alternatives 1.
That creates a tension for AI leaders. The CFO wants lower cost per task. The lab wants more token consumption. The worker wants tools that actually help. Training is where those interests can meet, but only if it teaches judgment about when to use the expensive model, when to route down, and when an agentic workflow creates enough new value to deserve the spend.
The real target is the known-ROI bias
The best phrase in the episode is "known ROI bias." Whittemore's warning is that caps do not merely limit spending. "Caps don't just limit spend, they shape what gets attempted," he says 1. When budgets tighten, employees tend to use AI on defensible, familiar tasks: summaries, drafts, support macros, analyst memos, code completion. Those may be useful, but they mostly make today's work a little faster.
Agentic value often requires a less comfortable kind of exploration. A product manager might spin up several agents to analyze customer logs, synthesize competitor changes, draft mock specs, and test adoption hypotheses. A finance team might build a recurring agent workflow that reconciles messy vendor data before a human signs off. A sales operations team might let agents test routing rules against historical pipeline outcomes. None of these start as clean ROI cases. They become ROI cases only after people are trained to experiment safely.
This is where the episode moves beyond generic "upskilling" language. Whittemore argues that agent management is closer to management training than software training 1. That is a useful distinction. The skill is not just knowing syntax or tool menus. It is defining work, assigning it, checking it, sequencing it, and intervening when the system drifts.
What the labs may have to do next
Whittemore predicts that over the next six to twelve months, OpenAI and Anthropic will increase investment in enablement, training, and expanding depth of usage 1. He also argues that forward-deployed engineering will not be enough. Central teams can build agents with enterprises, but they cannot discover every workflow inside a large company. The next wave has to be bottom-up.
That prediction is plausible because it follows the incentives. If labs need token growth, and enterprises will not tolerate waste, labs have to make users better. The likely playbook is not just documentation. Expect more hands-on labs, internal academies, workflow libraries, guided agent sandboxes, and dashboards that show whether usage is moving from low-value assistance to higher-value delegation.
There is an uncomfortable implication for enterprises, too. A spending cap without an experimentation program may look disciplined while quietly suppressing the workflows that would have made AI spending worthwhile. If the episode has one practical takeaway, it is this: budget control and training design have to be built together. Otherwise companies will teach employees to conserve tokens before they learn what tokens are for.
Bottom line
This episode is less about "AI education" as a category and more about the missing operating layer between infrastructure and value. Whittemore's argument is that the AI economy cannot be sustained by passive access, seat licenses, or a few forward-deployed engineering teams. It needs millions of workers who can manage agents well enough to make high-token workflows pay for themselves.
That may be overstated as macroeconomics, but it is directionally sharp as enterprise strategy. The next adoption bottleneck is not whether employees have an AI account. It is whether they know how to spend tokens with judgment.
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.